介绍
在爬虫过程中,难免会遇到各种各样的验证码,而大多数验证码还是图形验证码,这时候我们可以直接用 OCR 来识别。
tesserocr 是 Python 的一个 OCR 识别库 ,但其实是对 tesseract 做的一 层 Python API 封装,所以它的核心是 tesseract。 因此,在安装 tesserocr 之前,我们需要先安装 tesseract 。
例如:对于下图的验证码,我们可以通过 OCR 技术将其转换成电子文本,然后爬虫将识别的结果提交给服务器,便可以达到自动识别验证码的过程。
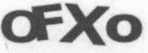
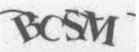
相关链接
tesserocr GitHub:
tesserocr PyPI:
tesseract 下载地址:
tesseract GitHub:
tesseract 语言包:
tesseract 文档:
Windows下的安装
在 Windows 下,首先需要下载 tesseract,它为 tesserocr 提供了支持。
进入下载页面,可以看到有各种 .exe 文件的下载列表,这里可以选择下载 3.0 版本 。 如下图所示为 3.05 版本 。
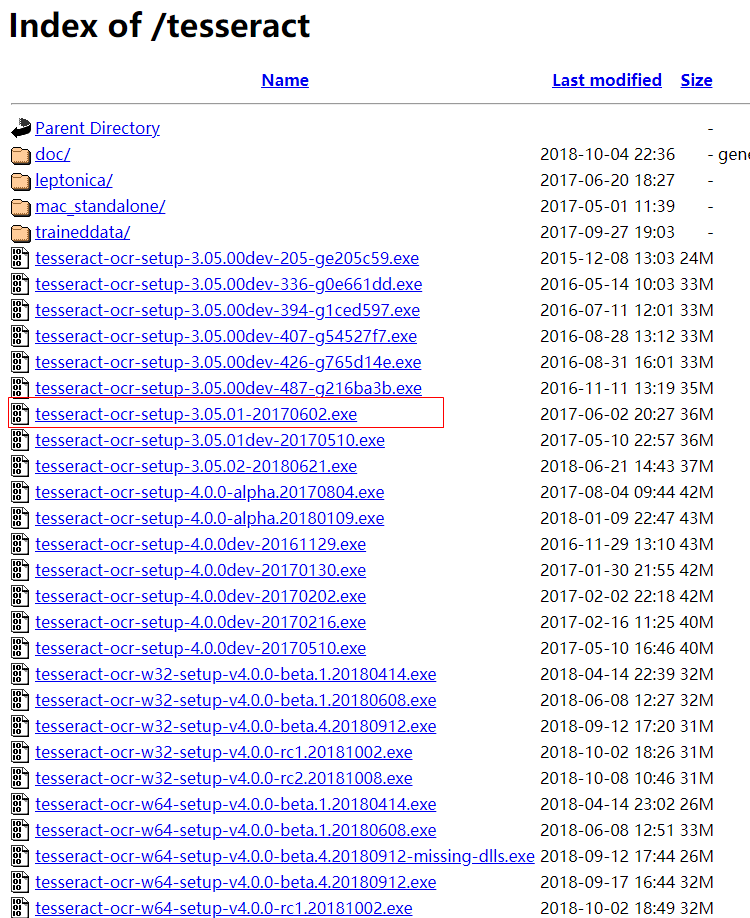
其中文件名中带有 dev 的为开发版本,不带 dev 的为稳定版本,可以选择下载不带 dev 的版本, 例如可以选择下载 tesseract-ocr-setup-3 .05.01.exe。
下载完成后双击运行,安装程序。需要注意的是,需要句选 Additional language data(download)选项来安装 OCR 识别支持的语言包,这样 OCR 便可以识别多国语言 。
给tesseract配置环境变量:
(1)将tesseract安装路径添加到path环境变量中

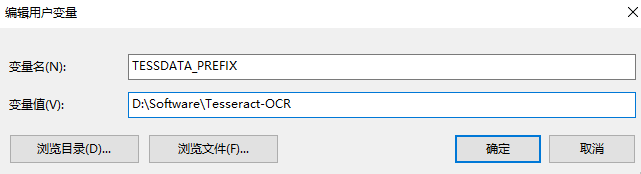
(2)将tesseract的语言包添加到环境变量中,在环境变量中新建一个系统变量,变量名称为TESSDATA_PREFIX,tessdata是放置语言包的文件夹,一般在你安装tesseract的目录下,即tesseract的安装目录就是tessdata的父目录,把TESSDATA_PREFIX的值设置为它即可
接下来 , 再安装 tesserocr 即可:
pip install tesserocr pillow
如果通过 pip 安装失败,可以尝试 Anaconda 下的 conda 来安装:
conda install -c simonflueckiger tesserocr pillow
验证安装
测试样例:

图片下载:
(1)用 tesseract 命令测试:
tesseract image.png result -l eng
运行结果如下:
Tesseract Open Source OCR Engine v3.05.01 with Leptonica
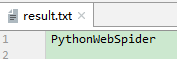
(2)利用 Python 代码测试:
import tesserocrfrom PIL import Imageimage = Image.open('image.png')result = tesserocr.image_to_text(image)print(result) 运行结果如下:
PythonWebSpider
另外,还可以直接调用 tesserocr 模块的 file_to_text() 方法,可以达到同样的效果:
import tesserocrprint(tesserocr.file_to_text('image.png')) 运行结果如下:
PythonWebSpider
如果成功输出结果,则证明 tesseract 和 tesserocr 都已经安装成功。